Lenguaje de programación: Cualquiera
Dificultad: Principiante
A* es uno de los algoritmos de búsqueda de caminos más conocidos del mundo, y aunque parece muy complicado al principio, es en realidad muy sencillo de entender.
En este artículo se explican las bases para entender cómo funciona y cómo implementarlo en cualquier lenguaje de programación. También daremos un paso más allá, explorando las maneras en las que se puede manipular para adaptarlo a nuestros casos de uso.
Índice
¿Qué es el Pathfinding o la Búsqueda de Caminos?
La búsqueda de caminos es el proceso de encontrar la secuencia de pasos que conectan dos puntos, A y B, sobre un medio definido por quien lo aplica.
Los medios más comunes son los grafos:
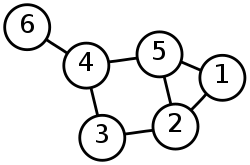
Las cuadrículas:


Y las mallas de navegación:
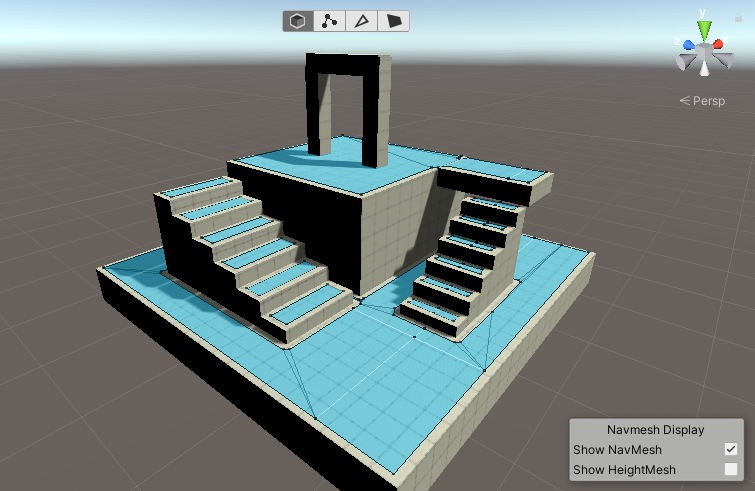
Todos estos medios se pueden reducir a la forma de un grafo con características adicionales. Por ejemplo, una cuadrícula podría ser un grafo donde cada nodo representa una celda, que tiene un número de subnodos llamados vértices, que tienen caminos que los unen, llamados aristas.
Por tanto, todos los algoritmos de búsqueda de caminos que encontremos trabajarán sobre grafos y serán lo suficiente abstractos para que podamos amoldarnos al medio que estemos trabajando.
Tipos de soluciones
Los algoritmos de búsqueda intentan encontrar el camino óptimo entre dos nodos de un grafo. En nuestro caso, óptimo será el que mejor se ajuste a nuestras necesidades, y esto no siempre será «el camino más corto».
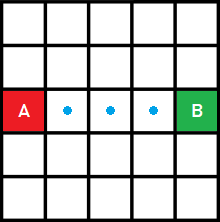
Imaginemos que trabajamos con una cuadrícula simple:
Cada casilla es una posición, y nos podremos mover de una posición a la siguiente en movimientos horizontales y verticales. Nos olvidaremos de los vértices, las aristas y los movimientos diagonales por ahora para simplificar.
Seleccionamos dos casillas llamadas A (en rojo) y B (en verde). El camino más corto entre estas dos posiciones sería el que está señalado en azul:
Ahora imaginemos que hay un obstáculo justo antes de llegar al punto B, una piedra enorme de color marrón que obstaculiza no una, sino tres celdas.
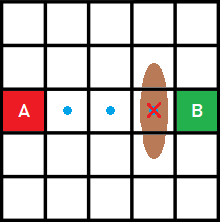
El camino más corto seguiría siendo el indicado en la imagen anterior. Sin embargo, ahora deberemos tener en cuenta que hay celdas que pueden tener el estado «bloqueado». Es decir, nuestro camino óptimo ya no será «aquel que sea más corto», sino «aquel que sea más corto y no pase por una celda bloqueada».
Es más, si te fijas, ya no tenemos una posible respuesta, ¡tenemos dos!
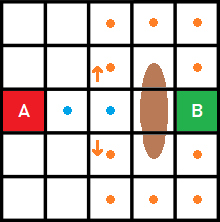
Ambas respuestas son igual de válidas, ¿pero cuál es la respuesta correcta?
Fácil: ¡Ambas!
Y es más, nuestro ejemplo es muy pequeño; en la realidad lo más probable es que un grafo pueda tener decenas de respuestas correctas al mismo tiempo.
Todo dependerá de la implementación del algoritmo y de cómo haya sido construido el grafo. Por norma general, los algoritmos miran los nodos vecinos de manera secuencial, por lo que si el grafo está construido de manera que el nodo al norte se compruebe antes que el nodo al sur, lo más probable es que elija el camino que pasa por el norte de la cuadrícula. Y viceversa, claro.
El caso de los obstáculos es el más habitual, pero hay muchos otros tipos de comportamientos que podemos querer representar para los que «el camino más corto» sería el más incorrecto.
Por ejemplo, imaginemos un agente que siempre debe caminar, por los menos, siete casillas antes de llegar a B:
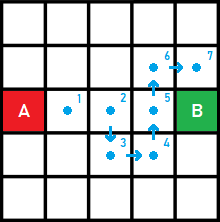
O que debe moverse como la pieza del caballo en el ajedrez, sin importar los obstáculos que encuentre:
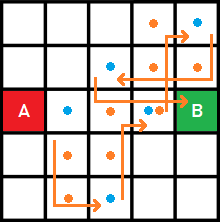
Veremos cómo implementar cualquier variación en el apartado sobre las funciones heurísticas.
¿Por qué A*?
Hay de todo; desde el clasiquísimo algoritmo de fuerza bruta que sólo se mueve en dirección a B, hasta sofisticados algoritmos que son capaces de calcular el movimiento de no sólo uno, sino de varios agentes a la vez, optimizando la distancia que caminan en conjunto. Es más, muchos algoritmos no se ejecutan sobre el grafo directamente sino que trabajan sobre reinterpretaciones del mismo, optimizando el tiempo de cálculo a costa de espacio en disco.
El mundo de los algoritmos de búsqueda de caminos es amplio y muy profundo. Así que, ¿por qué A*? ¿Qué tiene de especial?
Para una respuesta completa, deberíamos hablar de la Teoría de Grafos y hablar de varios algoritmos en profundidad. Este artículo no puede abarcarlo, pero la lectura citada en la oración anterior y ésta sobre Pathfinding te servirán si es algo que te interese estudiar.
La respuesta corta es que se trata de un algoritmo basado en el famoso algoritmo de búsqueda de Dijkstra, también llamado Búsqueda de Coste Uniforme. Es muy versátil y asequible, no requiere de preprocesar el grafo —¡aunque podrías!— y por lo general es muy eficiente. Hay algoritmos que trabajan mejor con cuadrículas, y otros que trabajan mejor con mallas, pero A* será lo bastante eficiente con cualquier cosa.
La característica definitoria del algoritmo A* es que utiliza el peso del paso entre dos nodos y la distancia ya recorrida para encontrar el camino. Si no se basa en estas dos cosas, no se trata de A*. Eso sí, tenemos muchísimas opciones para encontrar la distancia al destino; distancia euclidiana, de Chebyshev… por nombrarte un par, y mil maneras de influenciar el peso de pasar de un nodo a otro.
Por todo esto, A* suele ser la base de los algoritmos de búsqueda de caminos en el mundo de los videojuegos. Según avanza el desarrollo, lo normal es optimizar el grafo e incluso cambiar las metodologías de búsqueda, de manera que se transforma en otro algoritmo diferente. Eso no quita que A* sea un algoritmo excelente para iniciarse en los algoritmos de búsqueda de caminos.
Algoritmo A*, paso a paso
Utilizaremos de ejemplo un grafo como medio para A*, por ser el más versátil. Es fácil abstraer un grafo a una red de casillas o un navmesh.
Todos los algoritmos de búsqueda necesitan unos argumentos y devuelven un resultado. En el caso de A*, todo lo que necesita son los nodos A y B, y devolverá la lista de nodos que los unen.
A* utilizará dos listas para llevar la cuenta de los nodos visitados y el camino entre ellos. Estas listas utilizarán una estructura de datos para guardar: un nodo, el coste de llegar a él, y de qué otro nodo vienen.
En pseudocódigo:
clase AStarPath:
Nodo: N
Coste: float
Previo: AStarPath
función EsIgualQue que toma otro:AStarPath y devuelve bool
devuelve este.Nodo es igual a otro.NodoLa función EsIgualQue será necesaria para el algoritmo.
Las listas se llamarán listaAbierta y listaCerrada.
- listaAbierta es una lista ordenada, y guarda los nodos que tenemos por procesar. El orden será de menor a mayor en base al coste de llegar a cada nodo.
- listaCerrada es una lista normal, y guarda el camino que hemos seguido hasta B.
He aquí el pseudocódigo del algoritmo:
algoritmo A* que toma A:Nodo, B:Nodo y devuelve Lista:Nodos
primerNodo := AStarPath(A)
últimoNodo := AStarPath(B)
listaAbierta := ListaOrdenada:Nodos de Menor a Mayor, debe poder repetir valores
listaCerrada := Lista:Nodos
pivote := primerNodo
pivote.Anterior := nulo
pivote.Coste := 0
listaAbierta añade pivote
while listaAbierta no esté vacía y pivote no sea últinoNodo:
pivote := listaAbierta[0]
listaAbierta quita nodo en posición 0
listaCerrada añade pivote
si pivote no es últimoNodo:
nodoPivote := pivote.Nodo
for i entre 0 y el número de vecinos de nodoPivote:
otroNodo := vecino i de nodoPivote
vecino := AStarPath(otroNodo)
si listaCerrada no contiene vecino y listaAbierta no contiene vecino:
vecino.Previo := pivote
vecino.Coste := pivote.Coste + distancia(vecino, B)
listaAbierta añade vecino ordenado por el valor vecino.CosteCon estos pasos, lo que conseguimos es procesar siempre los siguientes nodos que generen menos coste para llegar a B. Sólo añadiremos a listaAbierta nodos nuevos no visitados antes, y sólo añadiremos a listaCerrada los mejores nodos, el camino final, para llegar a B.
Esta es la implementación más sencilla de A*. Puede haber casos en los que te interese volver a consultar nodos visitados antes, y actualizar su valor en la lista abierta. Recuerda que no se trata de un algoritmo rígido, sino que debe amoldarse a tus necesidades.
Todo lo que queda por hacer es coger listaCerrada y procesarla:
camino := Lista:Nodos
si pivote no es últimoNodo:
while pivote.Previo no sea nulo:
camino añade pivote.Nodo
pivote = pivote.Previo
camino añade A
invertir camino
devuelve camino - Creamos una lista de nodos.
- Mientras el nodo previo del pivote no sea null,
- Añadimos a la lista el nodo del pivote
- Pivote es ahora su previo.
- Añadimos el primer nodo para terminar.
- Revertimos la lista porque está ordenada del revés 😉
Y ya estaría.
¡Pero espera! Todavía podemos jugar mucho con este algoritmo. Hablemos de…
La Función Heurística
Ahora que tenemos la estructura básica del algoritmo, juguemos un poco con la heurística.
La función que hemos utilizado arriba es la distancia simple, la distancia Euclidea. Ha ocurrido en este punto:
vecino.Coste := pivote.Coste + distancia(vecino, B)Ésta es la función heurística de nuestro algoritmo. Nos permite discriminar nodos y afectar a cómo se ordenan en la lista abierta para que sean elegidos como mejores candidatos.
Para poder reutilizar el algoritmo con distintas heurísticas, puedes añadirla como uno de los argumentos del algoritmo, de manera que no se preocupe de cómo se calcula ese valor.
Así, esa línea pasa a ser:
vecino.Coste := pivote.Coste + heurística(vecino, B)Más funciones heurísticas
- Dale peso a los nodos, de manera que unos caminos sean más preferibles que otros;
distancia(vecino, B) + vecino.Peso - Dale peso a las aristas que unen los nodos;
distancia(vecino, B) + arista.Peso - Distancia Chebyshev
max(|vecino.x - B.x|, |vecino.y - B.y|) - Distancia Manhattan, como la distancia Euclídea pero utilizando valores absolutos
√ |(vecino.x - B.x)|^2 + |(vecino.y - B.y)|^2 - Bloquea nodos o aristas para que no puedan ser elegidos:
si vecino.Bloqueado o arista.Bloqueada:
devuelve Infinito Positivo
si no:
devuelve (otra heurística) - En vez de modificar la función heurística, ¡modifica el medio! Haz que las aristas del grafo sean direccionales, y sólo se puedan recorrer en una dirección.
- Si se puede llegar a un nodo desde más de una dirección, modifica A* para que AStarPath pueda recordar más de un camino
Si se te ocurre alguna más, ¡déjala en los comentarios!
Artículos relacionados
Esta es la teoría, pero ahora toca practicarla.
Aquí te dejo una serie de artículos en los que implementamos pathfinding:
- Unity: Un Grafo Genérico para todas tus necesidades de IA
- Unity: Mostrando el camino a nuestros NPCs.
Deja una respuesta